Στοιχειώδης ανάλυση ερωτηματολογίου με την R
Ως παράδειγμα δίνεται το ερωτηματολόγιο αξιολόγησης του μαθήματος Ηλεκτρονικοί Υπολογιστές II, κατά το εαρινό εξάμηνο 2010-11.
Τα δεδομένα είναι διαθέσιμα ως αρχείο csv. Μπορείτε να πάρετε με:
> se <- read.csv("http://stavrakoudis.econ.uoi.gr/stavrakoudis/evaluation/e2010-11-OIK207.csv", sep=";")
Οι διάφορες μεταβλητές (ερωτήματα) είναι διαθέσιμες με τα εξής ονόματα:
> names(se) [1] "q1" "q2" "q3" "q4" "q5_1" "q5_2" "q6_1" "q6_2" "q6_3" [10] "q6_4" "q6_5" "q6_6" "q6_7" "q6_8" "q6_9" "q6_10" "q6_11" "q7_1" [19] "q7_2" "q7_3" "q7_4" "q7_5" "q7_6" "q7_7" "q7_8" "q7_9" "q8_1" [28] "q8_2" "q8_3" "q8_4" "q8_5" "q8_6" "q8_7" "q8_8" "q8_9" "q8_10" [37] "q8_11" "q8_12" "q9_1" "q9_2" "q9_3" "q9_4" "q10" "q11_1" "q11_2" [46] "q11_3" "q11_4" "q11_5"
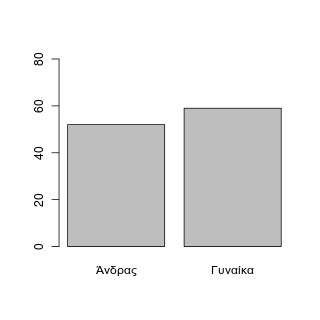
Η ερώτηση q1 αφορά το φύλλο, 1 για αγόρι και 2 για κορίτσι. Για να πάρετε το ραβδόγραμμα συχνοτήτων:
> sq1 <- table(se$q1)
barplot(sq1, ylim=c(0,80), names.arg=c("Άνδρας", "Γυναίκα"))
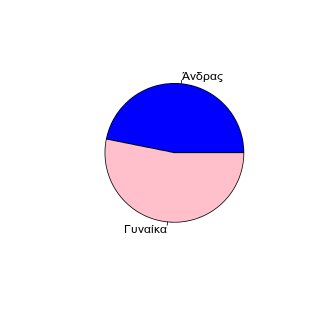
Αν θέλετε το διάγραμμα πίτας:
> sq1 <- table(se$q1)
> pie(sq1, labels=c("Άνδρας", "Γυναίκα"), col=c("blue","pink") )
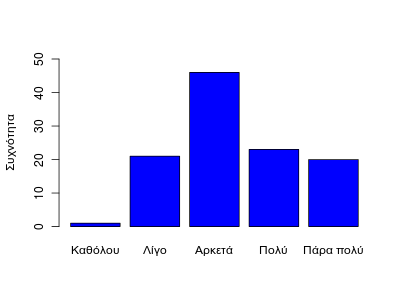
Σε ερωτήσεις με πολλές πιθανές απαντήσεις, τα διαγράμματα πίτας είναι συνήθως ακατάλληλα και προτιμούμε τα ραβδογράμματα συχνοτήτων. Πχ, η ερώτηση q6_1 (Αν το μάθημα χαρακτηρίζεται από δυσνόητες έννοιες) με απαντήσεις στην κλίμακα 1-5 (Λίγο ως Πάρα πολύ):
> sq6_1 <- table(se$q6_1)
> cat1 <- c ("Καθόλου", "Λίγο", "Αρκετά", "Πολύ", "Πάρα πολύ")
> barplot(sq6_1, names.arg=cat1, ylim=c(0,50), ylab="Συχνότητα", col=4)
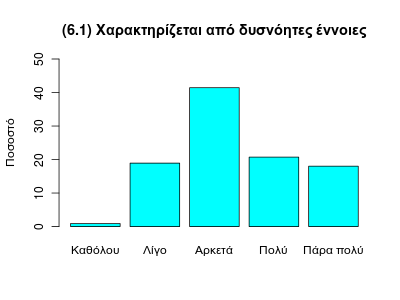
Μπορείτε επίσης να μετατρέψετε τις απόλυτες συχνότητες σε σχετικές (εδώ με ποσοστό %):
> sq6_1 <- table(se$q6_1)
> po6_1 <- 100*sq6_1/length(se$q6_1)
> cat1 <- c ("Καθόλου", "Λίγο", "Αρκετά", "Πολύ", "Πάρα πολύ")
> barplot(po6_1, names.arg=cat1, ylim=c(0,50), ylab="Ποσοστό", col=5)
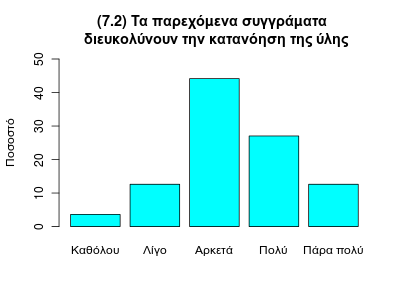
Ας δούμε μια ακόμα ερώτηση, πχ την 7.2, αν τα παρεχόμενα συγγράμματα διευκολύνουν την κατανόηση της ύλης:
> sq7_2 <- table(se$q7_2)
> po7_2 <- 100*sq7_2/length(se$q7_2)
> barplot(po7_2, names.arg=cat1, ylim=c(0,50), ylab="Ποσοστό", col=5,
main="(7.2) Τα παρεχόμενα συγγράματα \n διευκολύνουν την κατανόηση της ύλης")
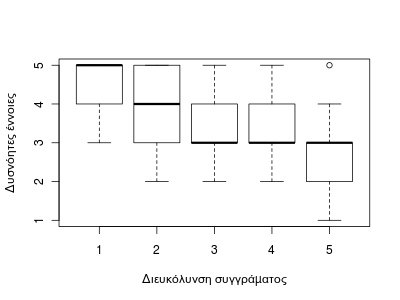
Πως θα μπορούσαμε να συγκρίνουμε τα δύο σύνολα απαντήσεων και να εξετάσουμε μια πιθανή σχέση τους; Δηλαδή, σχετίζεται η απάντηση στη ερώτηση 6.1 με την απάντηση 7.2; Ο απλούστερος τρόπος να δει κανείς κάτι τέτοιο είναι το boxplot:
> boxplot(se$q6_1 ~ se$q7_2, xlab="Διευκόλυνση συγγράμματος", ylab="Δυσνόητες έννοιες")
σχολιασμοί, εξωτερικοί σύνδεσμοι, βοήθεια, ψηφοφορίες, αρχεία, κτλ.

Εκπαιδευτικό υλικό από τον
Αθανάσιο Σταυρακούδη
σας παρέχετε κάτω από την άδεια
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 License.
Σας παρακαλώ να ενημερωθείτε για κάποιους επιπλέον περιορισμούς
http://stavrakoudis.econ.uoi.gr/stavrakoudis/?iid=401.